
Evolution of "Hello World" using random mutation and selection
Sometimes serendipity presents you with an opportunity to educate those who are confused by the claims of Intelligent Design and somewhat unfamiliar with evolutionary theory. So let me start with the answer and then look at the question.
Genetic Programming (GP) has a proven capability to routinely evolve software that provides a solution function for the specified problem. Prior work in this area has been based upon the use of relatively small sets of pre-defined operators and terminals germane to the problem domain. This paper reports on GP experiments involving a large set of general purpose operators and terminals. Specifically, a microprocessor architecture with 660 instructions and 255 bytes of memory provides the operators and terminals for a GP environment. Using this environment, GP is applied to the beginning programmer problem of generating a desired string output, e.g., “Hello World”. Results are presented on: the feasibility of using this large operator set and architectural representation; and, the computations required to breed string outputting programs vs. the size of the string and the GP parameters employed.
Genetic Evolution of Machine Language Software Ronald L. Crepeau NCCOSC RDTE Division San Diego, CA 92152-5000 July 1995
The Results?
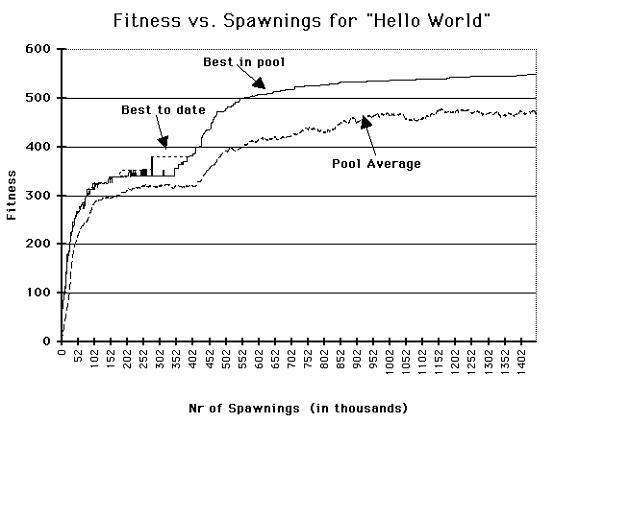
From Figure 5 it can be seen that this run achieved a correct output (fitness = 352) at about 150,000 spawnings (100 to 1200 generations). By about 450,000 spawnings, the agent was composed of less than 100 instructions. Ultimately, the agent size reduced to 58 instructions before the process was terminated.
Of course, the question proposed at Uncommon Descent is flawed for many reasons. In fact, an unfamiliarity with evolutionary theory combined with a false analogy quickly results in what is known as a strawman argument.
GilDodgen wrote:
What is the probability of arriving at our Hello World program by random mutation and natural selection?
Pretty darn good as I have shown.
GilDodgen wrote:
How many simpler precursors are functional, what gaps must be crossed to arrive at those islands of function, and how many simultaneous random changes must be made to cross those gaps? How many random variants of these 66 characters will compile? How many will link and execute at all, or execute without fatal errors? Assuming that our program has already been written, what is the chance of evolving it into another, more complex program that will compile, link, execute and produce meaningful output?
I’d love to see some research in this area. Appeal to ignorance is not really that appealing to me. These are excellent questions and should be answered before rejecting the plausibility in a somewhat ad hoc fashion. It’s time to abandon these ‘just so stories’ and do some real scientific work.
Of course, one may object to my choice of method and one may raise a myriad of objections based on the (unjustified) claim that the method required significant intelligent design or the fact that the fitness function is smooth, and so on but it shows that under ‘reasonable assumptions’ natural selection and variation can indeed create the required output string. In fact, this is hardly surprising given the state of knowledge about evolutionary computing.
Perhaps, it would be better if ID activists would present an argument based on an analogy which shows at least some minimum similarity with evolution such as for instance a redundant genotype-phenotype mapping, self-replications, and a way to introduce selection into the process in an acceptable format or replacing a single fixed goal with a more realistic evolutionary goal. As Lenski and others have shown however, that the processes of variation and chance can indeed generate complexity and even irreducibly complex systems.
In the end the question is not much dissimilar from Dawkin’s “Weasel” example and thus all known limitations apply. So what have we learned from this example?
- That a quick google search can once again answer many of the questions
- Intelligent Design once again excels at creating strawmen
- Intelligent Design once again lacks scientific relevance
- In fact, most of the argument was based on one from ignorance
GilDodgen wrote:
I can’t answer these questions, but this example should give you a feel for the unfathomable probabilistic hurdles that must be overcome to produce the simplest of all computer programs by Darwinian mechanisms.
While indeed the hurdles may appear intuitively to be unfathomable, it quickly becomes clear that a combined process of variation AND selection can be very efficient in overcoming these hurdles. Dawkins already showed this several decades ago.