
Counterexample to Mark Champneys’ argument about natural selection: more technical details
This post will supply some more technical details of my counterexample to Mark Champneys’ arguments that approach of physical and biological systems to equilibrium prevents natural selection from being effective. The counterexample is explained in my previous post. Below I provide the relevant equations and some simulation results showing what the effect of genetic drift will be. To avoid taking up too much space on the site’s front page, I will put most of that content “below the fold” …
Population genetics theory
The model had a very large (effectively infinite) population of haploid organisms, for which we are following 100 sites in their DNA. Mutation is symmetrical among all four possible nucleotides at rate u, with each mutational event equally likely to result in each of the other 3 possible bases. We are following the frequency of the C allele at each site. It has fitness a fraction s greater than the three other nucleotides, which have fitness 1. So the fitness of C is 1+s.
Each generation starts by producing a large number of offspring, with mutation happening at that time. So if the fraction of all copies of the site that have C is p, after mutation a fraction u of those have changed to another base, and a fraction u/3 of the non-C bases have changed and become C. Thus the frequency of allele C is then p’, where
p’ = p(1-u) + (u/3)(1-p)
Then these individuals undergo natural selection. (1-p’) of the copies are non-C bases, and p’ of the copies are C. As these have fitnesses 1 and 1+s, their numbers after selection will be proportional to (1-p’) and p’(1+s), so that the fraction of copies that are C will then become
p’(1+s) / ((1-p’) + p’(1+s)),
which is
p’(1+s) / (1 + p’ s).
Applying these two formulas in that order, we get after a full generation
(p(1-u) + (u/3)(1-p)) (1+s) / (1 + (p(1-u) + (u/3)(1-p)) s )
If we have reached the equilibrium gene frequency, this is again p, so that
p = (p(1-u) + (u/3)(1-p) )(1+s) / (1 + (p(1-u) + (u/3)(1-p)) s ).
Multiplying through by the denominator and collecting terms, after some struggle we end up with the quadratic equation
s(1-(4/3)u) p^2 + p( (4u/3) - s + (5/3)us) - (u/3)(1+s) = 0
Solving this for u = 0.0001 and s = 0, we get p = 1/4, the obvious answer from the symmetry of the mutational model. When s = 0.005, the equation becomes
0.004999333 p^2 - 0.00486583333 p - 0.0000335 = 0
whose positive root is the equilibrium frequency, p = 0.980133157.
Simulations showing the effect of genetic drift
If the 100 sites are far enough apart to have noticeable levels of recombination between them, and if their fitnesses combine multiplicatively, then each site can be regarded as evolving independently. If the population size is not infinite but, say, 20,000 then we can use a single-locus genetic simulation program such as the teaching program PopG produced by my laboratory. It is a Java application that can be downloaded from the site https://evolution.gs.washington.edu/popg/popg.html at our webserver.
The program is for a diploid population, but by making the diploid population size be
10,000 and making the fitnesses of the genotypes be powers of (1+s), it will give the same results as a haploid population twice the size and with fitnesses (1+s) ; 1. So I ran the program with 5 independent populations and 10,000 diploid individuals per population, and fitnesses of AA, Aa, and aa of 1.010025 : 1.005 : 1, and this is equivalent to having 20,000 haploid individuals with fitnesses 1.005 : 1 for A and a.
We have mutation rate from A to non-A of 0.0001 and from non-A to A of one-third that value,
0.000033333. Note that in these cases allele A stands in for the selectively favored base, C.
The figure below shows two runs, each with 5 populations, which is equivalent to following 5 sites:
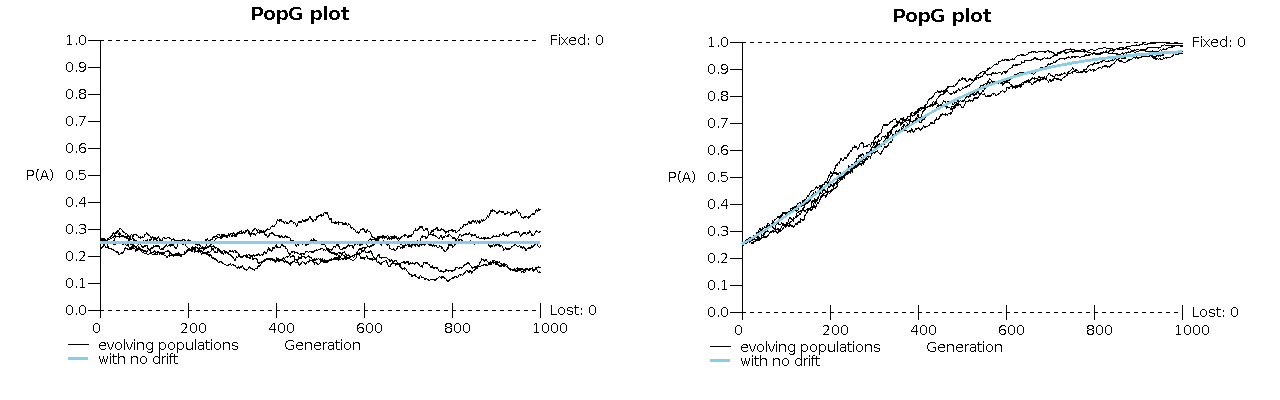
We see the mutational equilibrium in the absence of natural selection on the left, and the effect of selection with mutation in the figure on the right. The smooth blue curve shows what would have happened without genetic drift. With a larger population the individual sites would have remained closer to the smooth blue curves. The 50 individual sites will vary in gene frequency, as these 5 do, The result will be distributions a bit wider than the original binomial distributions.
Without genetic drift
In a very large population, where we can ignore genetic drift, each site has the frequency of the C allele change. At any generation, all 100 sites will have equal gene frequencies. Thus the distribution of the numbers of C’s in the haploid genomes will follow the binomial distribution, with 100 trials, each with a probability of C that is 1/4 (if there is no natural selection) or each with a probability of C that is 0.980133157. The state of the population will be a binomial distribution of the number of C’s, and this distribution will either approach an average of 25 C’s or an average of 98.0133157 C’s, depending on whether there is not or is natural selection. Like an idealized gas, the individuals will vary randomly, but the distribution of their properties will be a distribution that changes deterministically, from generation to generation.
Like gas in a container that is evenly distributed when there is no gravity, but collects at the bottom of the container if the whole thing is placed in a strong gravitational field, the population approaches an equilibrium which is different whether there is or is not natural selection. And that simple fact disproves the statements Mark Champneys made in his video about movement towards equilibrium preventing natural selection from having any long-term effect.